Screencast of the lecture

📚 Revision: multivariate calculus#
⏱ | words
References and additional materials

Revision of one-dimensional calculus: chapters 2, 3, 4
Chapters 13, 14

Appendix A.1, B.1, B.2
Veritasium video on paradoxes of set theory and mathematical incompleteness YouTube
Functions from \(\mathbb{R}\) to \(\mathbb{R}\)#
Definition
Let \(f \colon X \to \mathbb{R}\)
Let \(H\) be the set of all convergent sequences \(\{h_n\}\) such that \(h_n \ne 0\) and \(h_n \to 0\)
If there exists a constant \(f'(x)\) such that
for every \(\{h_n\} \in H\), then
\(f\) is said to be differentiable at \(x\)
\(f'(x)\) is called the derivative of \(f\) at \(x\)
We will use the following notation for derivative interchangeably
Definition
A function \(f \colon X \to \mathbb{R}\) is called differentiable (on \(X\)) if it is differentiable in all points of \(X\)
Differentiation rules#
Fact
For functions \(f(x)\), \(g(x)\) and \(h(x)\), and constant \(c\), we have
Scalar Multiplication Rule
Summation Rule:
Product Rule:
Quotient Rule:
Chain Rule:
The Inverse Function Rule:
Differentiability and continuity#
Just a reminder: by definition a function \(f: X \to \mathbb{R}\) is continuous in \(a\) if \(f(x) \to f(a)\) as \(x \to a\)
Fact
A differentiable function \(f \colon X \to \mathbb{R}\) is continuous on \(X\).
Converse is not true in general.
Proof
Consider a function \(f: X \longrightarrow \mathbb{R}\) where \(X \subseteq \mathbb{R}\). Suppose that
exists.
We want to show that this implies that \(f(x)\) is continuous at the point \(a \in X\). The following proof of this proposition is drawn from [Ayres Jr and Mendelson, 2013] (Chapter 8, Solved Problem 2).
First, note that
Thus we have
Now note that
Upon combining these two results, we obtain
Finally, note that
Thus we have
This means that \(f(x)\) is continuous at the point \(x=a\).
Consider the function
(There is no problem with this double definition at the point \(x=1\) because the two parts of the function are equal at that point.)
This function is continuous at \(x=1\) because
and
However, this function is not differentiable at \(x=1\) because
and
Since
we know that
does not exist.
\(\blacksquare\)
Higher order derivatives#
Consider a derivative \(f'(x)\) of a function \(f(x)\) as a new function \(g(x)\). We can then take the derivative of \(g(x)\) to obtain a second order derivative of \(f(x)\), denoted by \(f''(x)\).
Definition
Let \(f \colon X \to \mathbb{R}\) and let \(x \in (a, b)\)
A second order derivative of \(f\) at \(x\) denoted \(f''(x)\) or \(\frac{d^2 f}{dxdx}\) is the (first order) derivative of the function \(f'(x)\), if it exists
More generally, the \(k\)-th order derivative of \(f\) at \(x\) denoted \(f^{(m)}(x)\) or \(\frac{d^k f}{dx \dots dx}\) is the derivative of function \(\frac{d^{k-1} f}{dx \dots dx}\), if it exists
Definition
The function \(f: X \to \mathbb{R}\) is said to be of differentiability class \(C^m\) if derivatives \\(f', f'',\dots,f^{(m)}\) exist and are continuous on \(X\)
Taylor series#
Fact
Consider \(f: X \to \mathbb{R}\) and let \(f\) to be a \(C^m\) function. Assume also that \(f^{(m+1)}\) exists, although may not necessarily be continuous.
For any \(x,a \in X\) there is such \(z\) between \(a\) and \(x\) that
where the remainder is given by
Definition
Little-o notation is used to describe functions that approach zero faster than a given function
If \(f \colon \mathbb{R} \to \mathbb{R}\) is suitably differentiable at \(a\), then around \(a\) the linear and quadratic approximations are given by
Functions from \(\mathbb{R}^N\) to \(\mathbb{R}\)#
Extending the one-dimensional definition of derivative to multi-variate case is tricky!
With multiple variables, we have to decide which one to increment with the elements of the sequence \(\{h_n\}\)
We need a \(i\)-th unit vector of the form \((0, \dots, 0, 1, 0, \dots, 0)\) where \(1\) is in the \(i\)-th position to choose one particular variable
Definition
Let \(f \colon A \to \mathbb{R}\) and let \(x \in A \subset \mathbb{R}^N\). Denote \(e_i\) the \(i\)-th unit vector in \(\mathbb{R}^N\), i.e. \(e_i = (0, \dots, 0, 1, 0, \dots, 0)\) where \(1\) is in the \(i\)-th position.
If there exists a constant \(a \in \mathbb{R}\) such that
for every sequence \(\{h_n\}\), \(h_n \in \mathbb{R}\), such that \(h_n \ne 0\) and \(h_n \to 0\) as \(n \to \infty\), then \(a\) is called a partial derivative of \(f\) with respect to \(x_i\) at \(x\), and is denoted
Note the slight difference in notation \(\frac{d f}{d x}(x)\) of univariate derivative and \(\frac{\partial f}{\partial x_i}(x)\) of partial derivative
Partial derivatives behave just like regular derivatives of the univariate functions, assuming all variables except one are treated as constants
Usual rules of differentiation apply
Example
Partial derivatives are
However, the partial derivatives do not get it there all the way:
full analogue of the multivariate derivative to the univariate one should include all sequences converging to zero in the \(\mathbb{R}^N\) space?
what is the analogue of differentiability in the multivariate case, with the same implication to the continuety?
Definition
Let
\(A \subset \mathbb{R}^N\) be an open set in \(N\)-dimensional space
\(f \colon A \to \mathbb{R}\) be multivariate function
\(x \in A\), and so \(\exists \epsilon \colon B_{\epsilon}(x) \subset A\)
Then if there exists a vector \(g \in \mathbb{R}^N\) such that
for all converging to zero sequences \(\{h_n\}\), \(h_n \in B_{\epsilon}(0) \setminus \{0\}\), \(h_n \to 0\), then
\(f\) is said to be differentiable at \(x\)
vector \(g\) is called the gradient of \(f\) at \(x\), and is denoted by \(\nabla f(x)\) or simply \(f'(x)\)
note the dot product of \(g\) and \(h_n\) in the definition
the gradient is a vector of partial derivatives
Fact
If a function \(f \colon \mathbb{R}^N \to \mathbb{R}\) is differentiable at \(x\), then all partial derivatives at \(x\) exist and the gradient is given by
Proof
The idea of the proof: consider all converging sequences in \(\mathbb{R}^N\) and corresponding set of sequences in each dimension, component-wise.
Example
Continuing the previous example, the gradient is
Now, evaluating at a particular points (bold \({\bf 1}\) and \({\bf 0}\) denotes unit vector and zero vector in \mathbb{R}^3)
Fact
Sufficient conditions for differentiability of a function \(f \colon \mathbb{R}^N \to \mathbb{R}\) at \(x\) are that all partial derivatives exist and are continuous in \(x\)
Proof
The idea of the proof: consider all converging sequences in \(\mathbb{R}^N\) as composed component-wise from the converging sequences in each dimension, and verify that due to continuity, the vector of partial derivatives forms the vector \(g\) required by the definition of differentiability.
Directional derivatives#
To understand the role of the gradient of \(\mathbb{R}^N \to \mathbb{R}\) function, we need to introduce the concept of the directional derivative
Direction in \(\mathbb{R}^N\) can be given by any vector, after all vector has
absolute value (length)
direction
But we should focus on the unit vectors, i.e. vectors of length 1
Definition
Let
\(A \subset \mathbb{R}^N\) be an open set in \(N\)-dimensional space
\(f \colon A \to \mathbb{R}\) be multivariate function
\(x \in A\), and so \(\exists \epsilon \colon B_{\epsilon}(x) \subset A\)
\(v \in \mathbb{R}^N\) is a unit vector, i.e. \(\|v\| = 1\)
Then if there exists a constant \(D_v f(x) \in \mathbb{R}\) such that
then it is called a directional derivative of \(f\) at \(x\) in the direction of \(v\)
note that the step size \(h\) here is scalar
the directional derivative is a scalar as well
the whole expression \(\frac{f(x + hv) - f(x)}{h}\) can be thought of a derivative of univariate function of \(g(\tau)=f(x+\tau v)\)
the directional derivative is a simple (univariate) derivative of \(g(\tau)\) evaluated at \(\tau=0\)
Example
Let \(v = (\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}},0)\), that is we are interested in the derivative along the \(45^\circ\) line in the \(x\)-\(y\) plane. Note that \(\|v\|=1\).
After substitution of \(x+\tau v\) into \(f\), we get the function
Differentiating \(g(\tau)\) with respect to \(\tau\) gives
Finally, because we are interested in the derivative at the point \(x\) corresponding to \(\tau=0\), we have
Fact
Directional derivative of a differentiable function \(f \colon \mathbb{R}^N \to \mathbb{R}\) at \(x\) in given by
Proof
Main idea: carefully convert the limit from the definition of differentiability of \(f\) to the univariate limit in the definition of the directional derivative. The latter happens to equal the dot product of the gradient and the direction vector.
Example
Continuing the previous example, we have \(v = (\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}},0)\) and
Therefore, applying the formula \(D_v f(x) = \nabla f(x) \cdot v\) we immediately have
Fact
The direction of the fastest ascent of a differentiable function \(f \colon \mathbb{R}^N \to \mathbb{R}\) at \(x\) is given by the direction of its gradient \(\nabla f(x)\).
Proof
First, Cauchy–Bunyakovsky–Schwarz inequality for a Euclidean space \(\mathbb{R}^N\) states that for any two vectors \(u, v \in \mathbb{R}^N\) we have
where “\(\cdot\)” is dot product and \(\|x\| = \sqrt{x \cdot x}\) is the standard Euclidean norm.
Consider the case when at least one element of \(\nabla f(x)\) is positive, otherwise \(D_v f(x) = 0\) implying that the function does not increase in any direction.
For any unit direction vector \(v\) (in the same general direction as \(\nabla f(x)\) so that \(\nabla f(x) \cdot v >0\)), we have
The inequality is due to Cauchy–Bunyakovsky–Schwarz.
Now consider \(v = \frac{\nabla f(x)}{\|\nabla f(x)\|}\). For this direction vector we have
Thus, the upper bound on \(D_v f(x)\) is achieved when vector \(v\) has the same direction as gradient vector \(\nabla f(x)\). \(\blacksquare\)
Steepest descent algorithm uses the opposite direction of the gradient
Stochastic steepest descent algorithm uses the same idea (ML and AI applications!)
Functions from \(\mathbb{R}^N\) to \(\mathbb{R}^K\)#
Let’s now consider more complex case: functions from multi-dimensional space to multi-dimensional space
Definition
The vector-valued function \(f \colon \mathbb{R}^N \to \mathbb{R}^K\) is a tuple of \(K\) functions \(f_j \colon \mathbb{R}^N \to \mathbb{R}\), \(j \in \{1, \dots, K\}\)
We shall typically assume that the vector-valued functions return a column-vector
Definition
Let
\(A \subset \mathbb{R}^N\) be an open set in \(N\)-dimensional space.
\(f \colon A \to \mathbb{R}^K\) be a \(K\) dimensional vector function
\(x \in A\), and so \(\exists \epsilon \colon B_{\epsilon}(x) \subset A\)
Then if there exists a \((K \times N)\) matrix \(J\) such that
for all converging to zero sequences \(\{h_n\}\), \(h_n \in B_{\epsilon}(0) \setminus \{0\}\), \(h_n \to 0\), then
\(f\) is said to be differentiable at \(x\)
matrix \(J\) is called the Jacobian matrix (total derivative matrix) of \(f\) at \(x\), and is denoted by \(Df(x)\) or simply \(f'(x)\)
in this definition \(h_n\) is also a converging to zero sequence in \(\mathbb{R}^N\)
the difference is that in the numerator we have to use the norm to measure the distance in the \(\mathbb{R}^K\) space
instead of gradient vector \(\nabla f\) we have a \((K \times N)\) Jacobian matrix \(J\)
Similar to how the gradient, Jacobian is composed of partial derivatives
Fact
If a vector-valued function \(f \colon \mathbb{R}^N \to \mathbb{R}^K\) is differentiable at \(x\), then all partial derivatives at \(x\) exist and the Jacobian (total derivative) matrix is given by
note that partial derivatives of a vector-valued function \(f\) are indexed with two subscripts: \(i\) for \(f\) and \(j\) for \(x\)
index \(i \in \{1,\dots,K\}\) indexes functions and rows of the Jacobian matrix
index \(j \in \{1,\dots,N\}\) indexes variables and columns of the Jacobian matrix
Jacobian matrix is \((K \times N)\), i.e. number of functions in the tuple by the number of variables
the gradient is a special case of Jacobian with \(K=1\), as expected!
The sufficient conditions of differentiability are similar for vector-valued functions
Fact
Sufficient conditions for differentiability of a function \(f \colon \mathbb{R}^N \to \mathbb{R}^K\) at \(x\) are that all partial derivatives exist and are continuous in \(x\)
Total derivative (Jacobian) matrix of \(f \colon \mathbb{R}^N \to \mathbb{R}^K\) defines a linear map \(J \colon \mathbb{R}^N \to \mathbb{R}^K\) given by \(K \times N\) matrix \(Df(x)\) which gives a affine approximation of function \(f\) by a tangent hyperplane at point \(x\). This is similar to the tangent line to a one-dimensional function determined by a derivative at any given point.
Example
Partial derivatives are
Jacobian matrix is
Now, evaluating at a particular points (bold \({\bf 1}\) and \({\bf 0}\) denotes unit vector and zero vector in \(\mathbb{R}^3\))
Example
Exercise: Derive Jacobian maxtix of \(f\) and compute the total derivative of \(f\) at \(x = (1, 0, 2)\)
Rules of differentiation#
Fact: Sum and scaling
Let \(A\) denote an open set in \(\mathbb{R}^N\) and let \(f, g \colon A \to \mathbb{R}^K\) be differentiable functions at \(x \in A\).
\(f+g\) is differentiable at \(x\) and \(D(f+g)(x) = Df(x) + Dg(x)\)
\(cf\) is differentiable at \(x\) and \(D(cf)(x) = c Df(x)\) for any scalar \(c\)
Example
Jacobian matrix is
Consider the function \(g=f+f \colon \mathbb{R}^3 \to \mathbb{R}^2\). It is given by
Partial derivatives are
Jacobian matrix is
Clearly,
When it comes to the product rule, we have to specify which product is meant:
scalar product: multiplication of vector-valued function with a scalar function
dot product: multiplication of two vector-valued functions resulting in a scalar function
outer product: multiplication of column-vector-valued function and a row-vector-valued function resulting in a full matrix-valued function. The gradient of the matrix-valued function is a 3D array of partial derivatives, so we will skip this
Definition
Outer product of two vectors \(x \in \mathbb{R}^N\) and \(y \in \mathbb{R}^K\) is a \(N \times K\) matrix given by
Note
Potential confusion with products continues: in current context scalar product is a multiplication with a scalar (and not the product that produces a scalar as before in dot product of vectors)
Fact: Scalar product rule
Let
\(A\) denote an open set in \(\mathbb{R}^N\)
\(f \colon A \to \mathbb{R}\), differentiable at \(x \in A\)
\(g \colon A \to \mathbb{R}^K\), differentiable at \(x \in A\)
Then the product function \(fg \colon A \to \mathbb{R}^K\) is differentiable at \(x\) and
Observe that
\(\nabla f(x)\) is a \((1 \times N)\) vector
\(g(x)\) is a \((K \times 1)\) vector
therefore, \(g(x) \nabla f(x)\) is a \((K \times N)\) matrix (outer product!)
\(f(x)\) is scalar
\(Dg(x)\) is a \((K \times N)\) matrix
therefore \(f(x) Dg(x)\) is a \((K \times N)\) matrix
Example
Observe first that
Find all partials
Then the right hand side of the rule is
Exercise: continue to verify that the LHS of the rule gives identical expressions
Fact: Dot product rule
Let \(A\) denote an open set in \(\mathbb{R}^N\) and let \(f,g \colon A \to \mathbb{R}^K\) be both differentiable functions at \(x \in A\). Assume that both functions output column vectors.
Then the dot product function \(f \cdot g \colon A \to \mathbb{R}\) is differentiable at \(x\) and
where \(\square^{T}\) denotes transposition of a vector.
Observe that
both \(Dg(x)\) and \(Df(x)\) are \((K \times N)\) matrices
both \(f(x)^T\) and \(g(x)^T\) are \((1 \times K)\) row-vectors
therefore, both \(f(x)^T Dg(x)\) and \(g(x)^T Df(x)\) are \((1 \times N)\) row-vectors
Example
The dot product of the functions is given by
All the partials are
Now, to verify the rule,
Compositions of multivariate functions#
With multivariate functions, to correctly specify a composition, we have to worry about
domains and co-domains to correspond properly (as in one-dimensional case)
dimensions of the functions to correspond properly
Definition
Let \(A\) denote an open set in \(\mathbb{R}^N\) and \(B\) denote an open set in \(\mathbb{R}^K\)
Let \(f \colon A \to B\), and \(g \colon B \to \mathbb{R}^L\)
Then \(g \circ f\) is a well-defined composition of functions \(g\) and \(f\), and is given by
this definition works for any \(N\), \(K\), and \(L\)
including \(L=1\) corresponding a scalar-valued composition function, which contains vector-valued component
Fact: Chain rule
Let
\(A\) denote an open set in \(\mathbb{R}^N\)
\(B\) denote an open set in \(\mathbb{R}^K\)
\(f \colon A \to B\) be differentiable at \(x \in A\)
\(g \colon B \to \mathbb{R}^L\) be differentiable at \(f(x) \in C\)
Then the composition \(g \circ f\) is differentiable at \(x\) and its Jacobian is given by
Observe that
\(Dg\big(f(x)\big)\) is a \((L \times K)\) matrix
\(Df(x)\) is a \((K \times N)\) matrix
therefore the matrices are conformable for multiplication
the result is a \((L \times N)\) matrix, as expected
Example
Applying the chain rule
Now we can evaluate \(D(g \circ f)(x)\) at a particular points in \(\mathbb{R}^3\)
Example
Exercise: Using the chain rule, find the total derivative of the composition \(g \circ f\).
The chain rule is a very powerful tool in computing complex derivatives
Think backward propagation in deep neural networks!
Hessian matrix#
The higher order derivatives of the function in one dimension generalize naturally to the multivariate case, but the complexity of the needed matrixes and multidimensional arrays (tensors) grows fast.
Definition
Let \(A\) denote an open set in \(\mathbb{R}^N\), and let \(f \colon A \to \mathbb{R}\). Assume that \(f\) is twice differentiable at \(x \in A\).
The total derivative matrix of the gradient of function \(f\) at point \(x\), \(\nabla f(x)\) is called the Hessian matrix of \(f\) denoted by \(Hf\) or \(\nabla^2 f\), and is given by a \(N \times N\) matrix
Fact (Young’s theorem)
For every \(x \in A \subset \mathbb{R}^N\) where \(A\) is an open and \(f \colon A \to \mathbb{R}^N\) is twice continuously differentiable, the Hessian matrix \(\nabla^2 f(x)\) is symmetric
Example
Exercise: check
Example
Exercise: check
For the vector-valued function \(f \colon \mathbb{R}^N \to \mathbb{R}^K\) the first derivative is given by a \((K \times N)\) Jacobian matrix, and the second derivative is given by a \((K \times N \times N)\) tensor, containing \(K\) Hessian matrices, one for each \(f_j\) components. (this course only mentions this without going further)
Multivariate Taylor series#
Consider a function \(f\colon A \subset\mathbb{R}^N \to \mathbb{R}\) differentiable at \(x \in A\)
Introduce multi-index notation given vectors \(\alpha \in \mathbb{R}^N\) and \(x \in \mathbb{R}^N\)
\(|\alpha| \equiv \alpha_1 + \alpha_2 + \dots + \alpha_N\)
\(\alpha! \equiv \alpha_1! \cdot \alpha_2! \cdot \dots \cdot \alpha_N!\)
\(x^{\alpha} \equiv x_1^{\alpha_1} x_2^{\alpha_2} \dots x_N^{\alpha_N}\)
Fact (Clairaut theorem)
If all the \(k\)-th order partial derivatives of \(f\) exist and are continuous in a neighborhood of \(x\), then the order of differentiation does not matter, and the mixed partial derivatives are equal
Therefore the following notation for the up to \(k\) order partial derivatives is well defined
In these circumstances (that Clairaut/Young theorem applies for all \(k = 1,2,\dots,k\)) we say that \(f\) is \(k\)-times differentiable at \(x\)
Fact
Let \(f\colon A \subset\mathbb{R}^N \to \mathbb{R}\) be a \(k\)-times continuously differentiable function at a point \(a \in \mathbb{R}^N\). Then there exist functions \(h_\alpha \colon \mathbb{R}^N \to \mathbb{R}\), where \(|\alpha|=k\) such that
where \(\lim_{x \to a}h_\alpha(x) = 0.\)
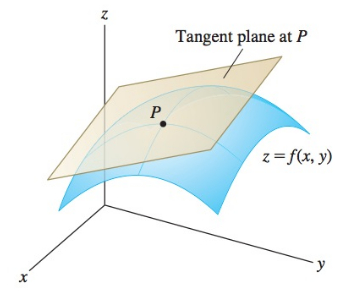
Fig. 32 Linear approximation of the a 3D surface with a tangent plane#
Example
The second-order Taylor polynomial of a smooth function\(f:\mathbb R^N\to\mathbb R\)
Let \(\boldsymbol{x}-\boldsymbol{a}=\boldsymbol{v}\)
Example
The third-order Taylor polynomial of a smooth function\(f:\mathbb R^2\to\mathbb R\)
Let \(\boldsymbol{x}-\boldsymbol{a}=\boldsymbol{v}\)
Source: Wiki