Announcements & Reminders
Online test 2 this week on Sunday, March 30 😬
covers material from the last three weeks
Matrix arithmetics
Multivariate differentiation
Vector spaces and linear operators
Egienvectors and diagonalization
DO NOT FORGET
postponed tests only when validated by ANU’s procedure
On short answer question write exactly what is asked
Single word is one and only on word!
Check your spelling
Next two weeks are teaching break 🎉
Good time to go over the material you struggle with, read the textbook and look through the extra material (3Blue1Brown videos)
Semester continues on Monday, April 14
However, I will be away
The lecture will be face-to-face, taught by my PhD student and tutor Wending Liu
The week after that is Easter, April 21 lecture will be recorded
I will see you in person on April 28
Online test 3 is on Sunday, April 27 😬
will cover material from the previous two weeks
Unconstrained optimization
Convexity and uniqueness
DO NOT FORGET
postponed tests only when validated by ANU’s procedure
Stay tuned to course announcements on Wattle
📖 Eigenvalues and diagonalization#
⏱ | words
References and additional materials

Chapters 10.4 to 10.7, 23.1, 23.3, 23.4, 23.7

Appendix C.2, C.3, C.4
Excellent visualizations of concepts covered in this lecture, strongly recommended for further study 3Blue1Brown: Essence of linear algebra
Euclidean Space#
We looked at vector spaces in the last lecture:
Linear combination
Span
Linear independence
Basis and dimension
Linear transformations
Now we add an additional component to the mix: dot/inner product \(\implies\) Euclidean space
Definition
The Euclidean space is a pair \((V,\boldsymbol{\cdot})\) where \(V\) is a vector space and “\(\boldsymbol{\cdot}\)” is a function from \(V \times V\) to \(\mathbb{R}\) that satisfies the following properties:
For all \(u,v,w \in V\) and \(\alpha, \beta \in \mathbb{R}\):
“\(\boldsymbol{\cdot}\)” is symmetric: \(u \boldsymbol{\cdot} v = v \boldsymbol{\cdot} u\)
“\(\boldsymbol{\cdot}\)” is linear: \((\alpha u + \beta v) \boldsymbol{\cdot} w = \alpha (u \boldsymbol{\cdot} w) + \beta v \boldsymbol{\cdot} w\)
“\(\boldsymbol{\cdot}\)” is positive definite: \(u \boldsymbol{\cdot} u \geq 0\) and \(u \boldsymbol{\cdot} u = 0 \iff u = 0\)
Thus, the difference between vector space and Euclidean space is the inclusion of an additional binary operation on the elements of the vector space.
Dot (inner) product#
The standard name for the additional operation is dot product or inner product
Sometimes Euclidean spaces are also referred to as dot product or inner product spaces
Definition
The dot product (inner product) of two vectors \(x, y \in \mathbb{R}^n\) is
the notation \(\square^T\) is transposition operation which flips the vector from column-vector to row-vector to allow for standard matrix application to apply
alternative notation that you can come across is \(\square^\prime\)
We can verify that the following properties hold for the dot product (as required by the definition of Euclidean space):
Fact: Properties of dot product
For any \(\alpha, \beta \in \mathbb{R}\) and any \(x, y \in \mathbb{R}^n\), the following statements are true:
\(x^T y = y^T x\)
\((\alpha x)^T (\beta y) = \alpha \beta (x^T y)\)
\(x^T (y + z) = x^T y + x^T z\)
Norm#
Dot product allows us to measure distance in the Euclidean space!
Definition
The (Euclidean) norm of \(x \in \mathbb{R}^n\) is defined as
As before
\(\| x \|\) represents the ``length’’ of \(x\)
\(\| x - y \|\) represents distance between \(x\) and \(y\)
Fact
For any \(\alpha \in \mathbb{R}\) and any \(x, y \in \mathbb{R}^n\), the following statements are true:
\(\| x \| \geq 0\) and \(\| x \| = 0\) if and only if \(x = 0\)
\(\| \alpha x \| = |\alpha| \| x \|\)
\(\| x + y \| \leq \| x \| + \| y \|\) (triangle inequality)
\(| x^T y | \leq \| x \| \| y \|\) (Cauchy-Schwarz inequality)
Example
By default vectors are usually thought of as column-vectors:
Triangle inequality:
Cauchy-Schwarz inequality:
Fact
Dot products of linear combinations satisfy
Proof
Follows from the properties of the dot product after some simple algebra
Orthogonality#
Definition
Consider an Euclidean space \((V, \boldsymbol{\cdot})\). Two vectors \(x, y \in V\) are called to as orthogonal if
based on the geometric interpretation of dot product as the product of vector norms by the cosine of the angle between them, we can see that orthogonality implies that the angle between the vectors is \(90^{\circ}\)
Example
The elements of canonical basis in \(\mathbb{R}^n\) are orthogonal to each other (pairwise orthogonal).
Indeed, take any \(e_i\), \(e_j\), \(i \ne j\), from the canonical basis. These are both vectors with mainly zeros, and a single 1 in the \(i\)-th and \(j\)-th positions, respectively. Applying the dot product definition, the resuls is obviously zero.
Fact
Fix \(a \in \mathbb{R}^n\) and let \(A = \{ x \in \mathbb{R}^n \colon a^T x = 0 \}\)
The set \(A\) is a linear subspace of \(\mathbb{R}^n\)
Proof
Let \(x, y \in A\) and let \(\alpha, \beta \in \mathbb{R}\)
We must show that \(z = \alpha x + \beta y \in A\)
Equivalently, that \(a^T z = 0\)
True because
\(a\) is referred to as the normal to the \(n-1\)-dimensional hyperplane \(A\)
Example
In \(\mathbb{R}^3\) let \(a=(2,-1,5)\), then \(A\) is given by an equation \(2x - y + 5z = 0\) which is a plane in 3D space.
Orthonormal basis#
Definition
A set \(\{x_1, x_2, \dots, x_m\}\) where \(x_j \in \mathbb{R}^n\) is called orthogonal set if each pair of vectors in the set is orthogonal
Definition
Consider a Euclidean space \((V,\boldsymbol{\cdot})\).
Orthogonal basis on \((V,\boldsymbol{\cdot})\) is any basis on \(V\) which is also an orthogonal set.
Orthonormal basis on \((V,\boldsymbol{\cdot})\) is any orthogonal basis on \(V\) all vectors of which have unit norm.
Example
Canonical basis in \(\mathbb{R}^n\) is an example of an orthonormal basis.
Clearly, the dot product between each two vectors is zero, and each vector has norm \(\sqrt{0+\dots+0+1^2+0+\dots+0}=1\).
Example
Consider the set \(\left\{ \left( \begin{array}{c} 1 \\ 2 \end{array} \right), \left( \begin{array}{c} -2 \\ 1 \end{array} \right) \right\}\). It’s easy to check that they are linearly independent and therefore form a basis in their span (which is \(\mathbb{R}^2\)).
The dot product of these two vectors is \(1 \cdot (-2) + 2 \cdot 1 = 0\), hence they are orthogonal. But this is not a orthonormal basis because the vectors do not have unit norm.
We could normalize the vectors to get an orthonormal basis. First compute the norm of each:
Therefore the orthonormal basis “based on” the original set is
Change of basis#
Coordinates of vector depend on the basis used to represent it
We can change the basis and thus the coordinates of the vector
This is like speaking different languages: the same vector can be represented by different coordinates
Let’s learn to translate between these languages!
Example
Think of number systems with different bases: the same number can be represented with different digit
Base of number syste \(\leftrightarrow\) basis in vector space: not fundamental, just a convention
Consider a vector \(x\in \mathbb{R}^n\) which has coordinates \((x_1,x_2,\dots,x_n)\) in canonical basis \((e_1,e_2,\dots,e_n)\), where \(e_i = (0,\dots,0,1,0\dots,0)^T\)
Definition
Coordinates of a vector are the coefficients of the linear combination of the basis vectors that is equal to the vector.
Recall (which fact?) that uniqueness of representation holds for any linear combinations, not only basis.
We have
Consider a different basis in \(\mathbb{R}^n\) denoted \((e'_1,e'_2,\dots,e'_n)\). By definition it must be a set of \(n\) vectors that span the whole space (and are therefore linearly independent).
When writing \(e'_i\) we imply that each \(e'_i\) is written in the coordinates corresponding to the original basis \((e_1,e_2,\dots,e_n)\).
The coordinates of vector \(x\) in basis \((e'_1,e'_2,\dots,e'_n)\) denoted \(x' = (x'_1,x'_2,\dots,x'_n)\) are by definition
Definition
The transformation matrix from basis \((e'_1,e'_2,\dots,e'_n)\) to the basis \((e_1,e_2,\dots,e_n)\) is composed of the coordinates of the vectors of the former basis in the latter basis, placed as columns:
\(P\) translates new coordinates back to the existing coordinates (so that we can make sense what the vector is)
In other words, the same vector has coordinates \(x = (x_1,x_2,\dots, x_n)\) in the original basis \((e_1,e_2,\dots,e_n)\) and \(x' = (x'_1,x'_2,\dots, x'_n)\) in the new basis \((e'_1,e'_2,\dots,e'_n)\), and it holds
We now have a way to represent the same vector in different bases, i.e. change basis!
Example
The opposite transformation is possible due to the following fact.
Fact
The transformation matrix \(P\) is nonsingular (invertible).
Proof
Because the transformation matrix maps a set of basis vectors to another set of basis vectors, they are linearly independent. By the properties of linear functions, \(P\) is then non-singular, and \(P^{-1}\) exists. \(\blacksquare\)
Linear functions in different bases#
Consider a linear map \(A: x \mapsto Ax\) where \(x \in \mathbb{R}^n\)
Can we express the same linear map in a different basis?
Let \(B\) be the matrix representing the same linear map in a new basis, where the transformation matrix is given by \(P\).
If the linear map is the same, can convert the argument to new basis, apply the \(B\) transformation, and convert back to the orginal basis:
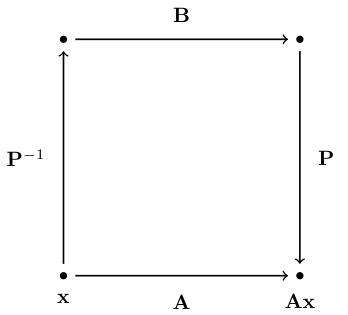
Definition
Square matrix \(A\) is said to be similar to square matrix \(B\) if there exist an invertible matrix \(P\) such that \(A = P B P^{-1}\).
Similar matrixes happen to be very useful when we can convert the linear map to a diagonal form which may be much easier to work with (see below)
Change to orthonormal basis#
Interesting things happen when we change basis to the orthonormal one.
Let \(\{s_1,\dots,s_n\}\) be an orthonormal basis in \(\mathbb{R}^n\). These vectors form columns of the transformation matrix \(P\). Consider \(P^TP\), and using the fact that \(\{s_1,\dots,s_n\}\) is an orthogonal set of vectors with norm equal one, we have
Definition
The matrix for which it holds
is called orthogonal matrix.
The transformation matrix \(P\) from the original basis to the orthonormal basis is an orthogonal matrix.
Example
Consider the previous example of the orthonormal basis
The transformation matrix \(P\) is
Let’s check if the transformation matrix \(P\) is orthogonal:
The implication of these facts is that the change of basis to the orthonormal one is particularly easy to perform: no need to invert the transformation matrix, just transpose it!
In other words, the same vector has coordinates \(x = (x_1,x_2,\dots, x_n)\) in the original basis \((e_1,e_2,\dots,e_n)\) and \(x' = (x'_1,x'_2,\dots, x'_n)\) in the new orthonormal basis \((e'_1,e'_2,\dots,e'_n)\), and it holds
Let \(A\) and \(B\) be the matrixes representing the same linear map in the original and new orthonormal basis with the transformation matrix given by \(P\).
It holds
This explains the wide use of orthonormal basis in practice
Eigenvalues and Eigenvectors#
Let \(A\) be a square matrix
Think of \(A\) as representing a mapping \(x \mapsto A x\), this is a linear function (see prev lecture)
But sometimes \(x\) will only be scaled in the transformation:
Definition
If \(A x = \lambda x\) holds and \(x \ne {\bf 0}\), then
\(x\) is called an eigenvector of \(A\) and \(\lambda\) is called an eigenvalue
\((x, \lambda)\) is called an eigenpair
Clearly \((x, \lambda)\) is an eigenpair of \(A\) \(\implies\) \((\alpha x, \lambda)\) is an eigenpair of \(A\) for any nonzero \(\alpha\), so infinitely many eigenvectors for each eigenvalue, forming infinitely many eigenpairs.
Example
Let
Then
form an eigenpair because \(x \ne 0\) and
import numpy as np
A = [[1, 2],
[2, 1]]
eigvals, eigvecs = np.linalg.eig(A)
for i in range(eigvals.size):
x = eigvecs[:,i]
lm = eigvals[i]
print(f'Eigenpair {i}:\n{lm:.5f} --> {x}')
print(f'Check Ax=lm*x: {np.dot(A, x)} = {lm * x}')
Eigenpair 0:
3.00000 --> [0.70710678 0.70710678]
Check Ax=lm*x: [2.12132034 2.12132034] = [2.12132034 2.12132034]
Eigenpair 1:
-1.00000 --> [-0.70710678 0.70710678]
Check Ax=lm*x: [ 0.70710678 -0.70710678] = [ 0.70710678 -0.70710678]
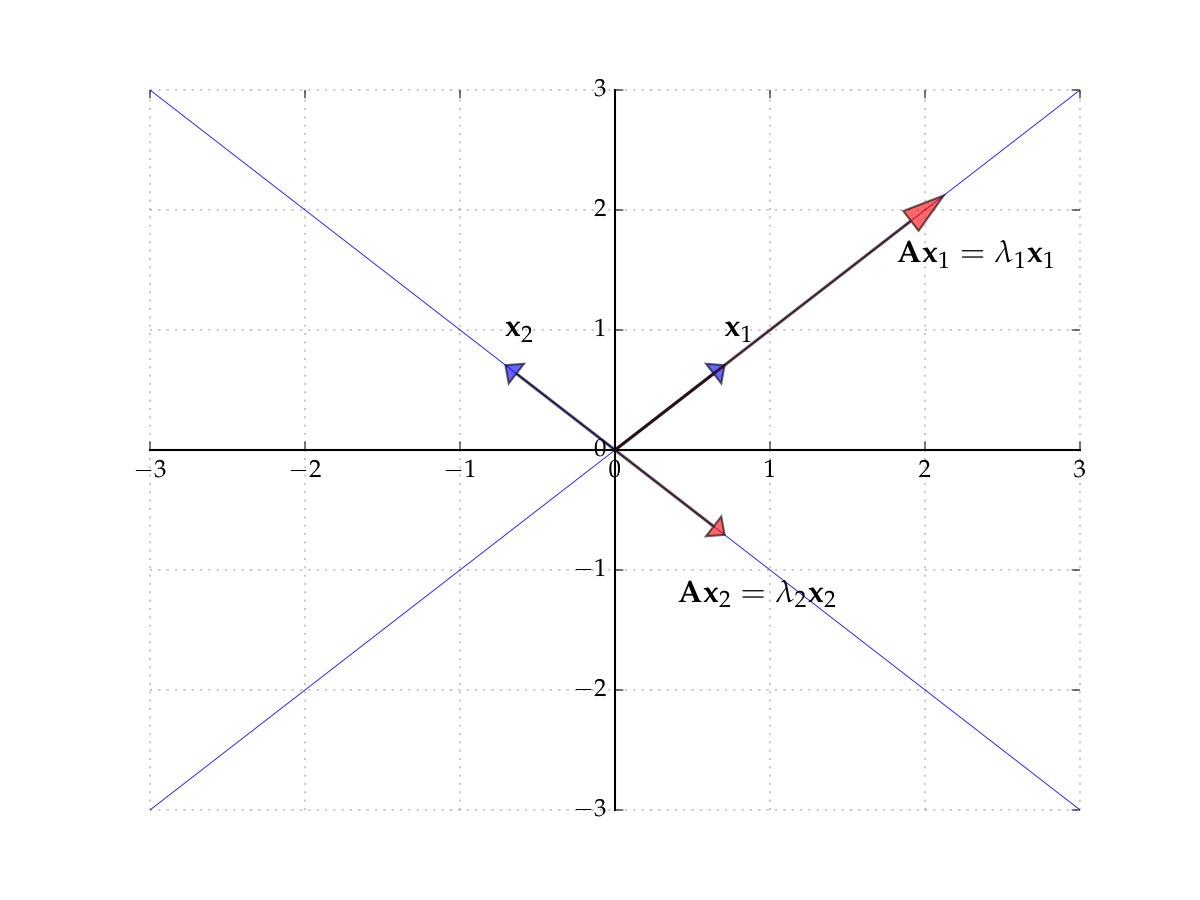
Fig. 46 The eigenvectors of \(A\)#
Consider the matrix
Induces counter-clockwise rotation on any point by \(90^{\circ}\)
Hint
The columns of the matrix show where the classic basis vectors are translated to.
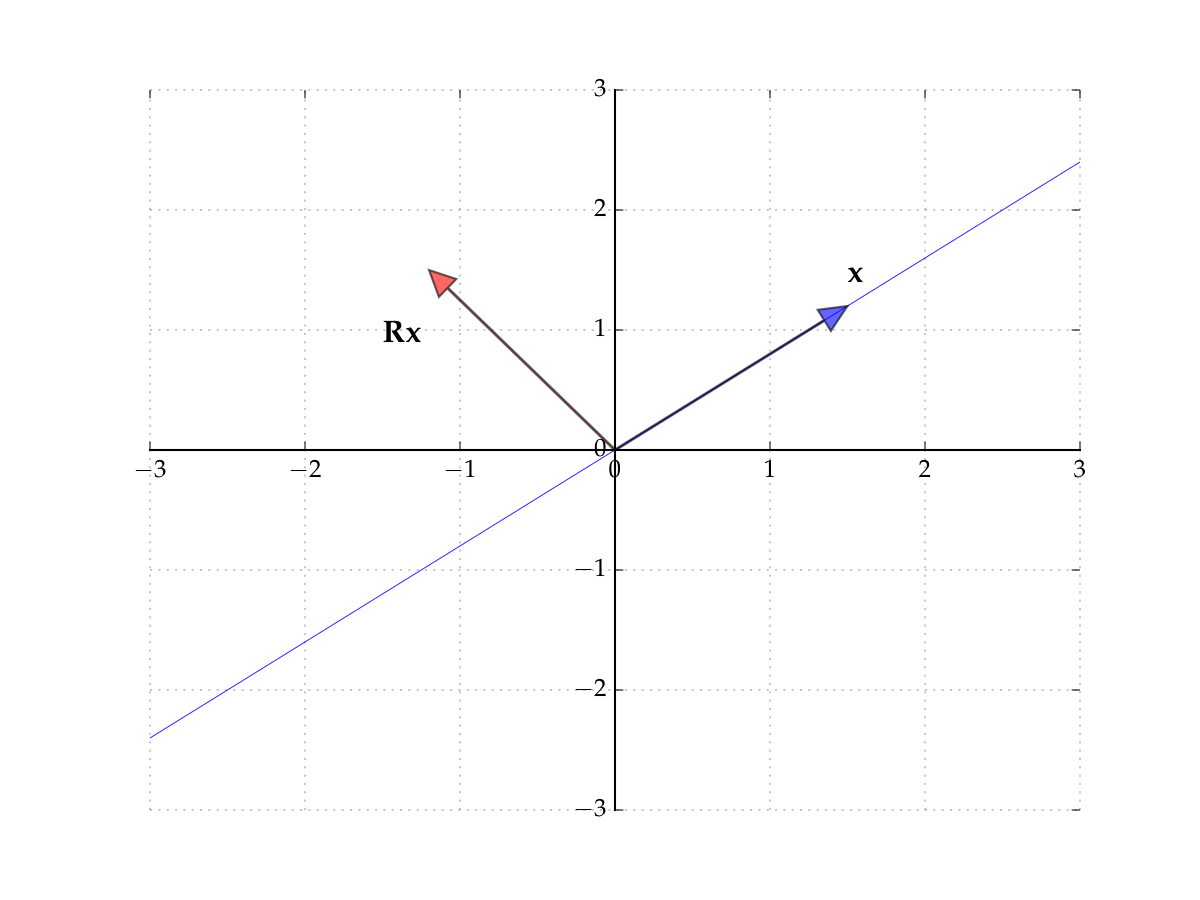
Fig. 47 The matrix \(R\) rotates points by \(90^{\circ}\)#
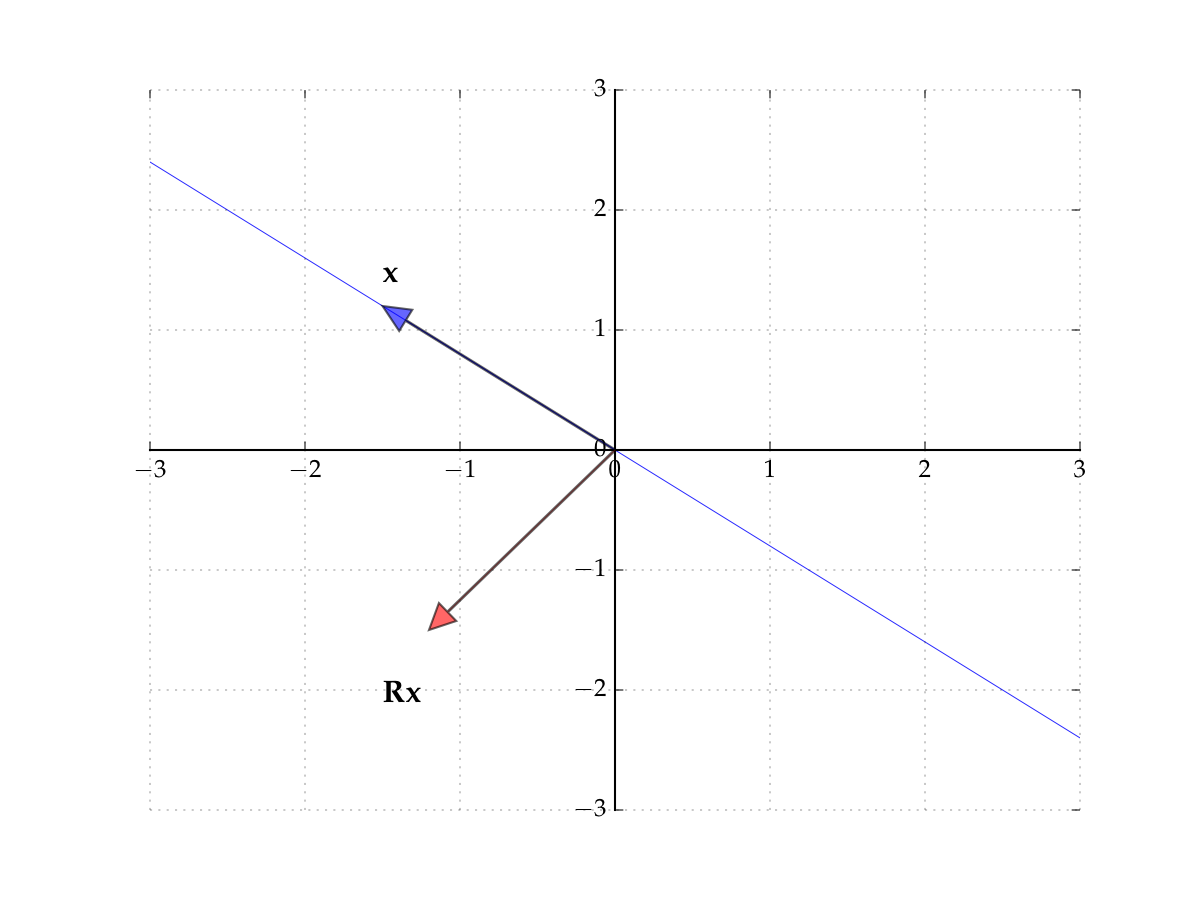
Fig. 48 The matrix \(R\) rotates points by \(90^{\circ}\)#
Hence no point \(x\) is scaled
Hence there exists no pair \(\lambda \in \mathbb{R}\) and \(x \ne 0\) such that
In other words, no real-valued eigenpairs exist. However, if we allow for complex values, then we can find eigenpairs even for this case as well.
Finding eigenvalues#
Fact
For any square matrix \(A\)
Proof
Let \(A\) by \(n \times n\) and let \(I\) be the \(n \times n\) identity matrix
We have
Example
In the \(2 \times 2\) case,
Hence the eigenvalues of \(A\) are given by the two roots of
Equivalently,
Example
Consider the matrix
Note that \(\mathrm{trace}(A)=5\) and \(\det(A)=6\). The eigenvalues solve
Existence of Eigenvalues#
For an \((n \times n)\) matrix \(A\) expression \(\det(A - \lambda I) = 0\) is a polynomial equation of degree \(n\) in \(\lambda\)
to see this, imagine how \(\lambda\) enters into the computation of the determinant using the definition along the first row, then first row of the first minor submatrix, and so on
the highest degree of \(\lambda\) is then the same as the dimension of \(A\)
Definition
The polynomial \(\det(A - \lambda I)\) is called a characteristic polynomial of \(A\).
The roots of the characteristic equation \(\det(A - \lambda I) = 0\) determine all eigenvalues of \(A\).
By the Fundamental theorem of algebra there are \(n\) of such (complex) roots \(\lambda_1, \ldots, \lambda_n\), and we can write
Each such \(\lambda_i\) is an eigenvalue of \(A\) because
not all roots are necessarily distinct — there can be repeats
Fact
By the fundamental theorem of algebra, every square \(n \times n\) matrix has \(n\) eigenvalues counted with (algebraic) multiplicity in the field of complex numbers \(\mathbb{C}\).
So, there are two cases to be aware of:
eigenvalues with multiplicity greater than 1
eigenvalues that are not real numbers
Example
Consider the matrix
The characteristic polynomial is
Therefore, both roots are \(2\) and thus there is only eigenvalue. In this case we say that the eigenvalue has algebraic multiplicity 2.
Example
Consider the matrix
The characteristic polynomial is
Therefore, both roots are not real numbers. The eigenvalues are \(\lambda = 2 \pm \sqrt{-1} \in \mathbb{C}\).
Fact
Characteristic polynomial \(\det(A-\lambda I)\) does not change with the change of basis.
Proof
Let \(B\) represent the same linear map as \(A\) in the new basis, and let \(P\) be a transformation matrix from the original basis to the new basis. We have \(A = P B P^{-1}\).
Due to the properties of the determinant we have
\(\blacksquare\)
Fact
If \(A\) is nonsingular, then eigenvalues of \(A^{-1}\) are \(1/\lambda_1, \ldots, 1/\lambda_n\)
Proof
Finding eigenvectors from eigenvalues#
Once we know the eigenvalues, we may want to find eigenvectors that correspond to them.
Approach: plug the eigenvalue back into the equation \((A-\lambda I) x = 0\) and solve for \(x\)
we should not expect this system to have a single solution since \(A-\lambda I\) is by definition singular
but we can recover a subspace of solutions that correspond to the given eigenvector
it is possible that multiple vectors correspond to the same eigenvalue
Example
We showed above that
has two distinct eigenvalues \(\lambda_1 = 2\) and \(\lambda_2 = 3\). Let’s find the eigenvectors corresponding to these eigenvalues.
The system places no restriction on \(x_1\), and so any vector \((p,0)\) is a solution, \(p\) is a free parameter. Therefore any vector of the form \((p,0)\) is an eigenvector corresponding to \(\lambda_1 = 2\).
The system only requires \(-x_1 + x_2 = 0\), that is \(x_1=x_2\), therefore any vector of the form \((p,p)\) is a solution, and an eigenvector corresponding to \(\lambda_2 = 3\).
Example
For the matrix
the characteristic polynomial is \((\lambda-3)^2\), and therefore there is one eigenvalues \(\lambda = 3\) with multiplicity 2. Let’s find the eigenvectors corresponding to these eigenvalues.
The system places no restriction on either \(x_1\) or \(x_2\), and any vector \((x_1,x_2)\) is an eigenvector corresponding to \(\lambda = 3\)!
This is the case when it is possible to find a basis of two vectors in the linear subspace corresponding to the eigenvalue \(\lambda = 3\), for example \((1,0)\) and \((0,1)\).
In this case we say that the eigenvalue has geometric multiplicity 2.
Geometrically, the linear transformation corresponding to the matrix \(A\) stretches the space in both directions by the factor of 3.
Diagonalization#
Putting together eigenpairs and change of basis for the better good!
Diagonal matrixes#
Consider a square \(n \times n\) matrix \(A\)
Definition
The \(n\) elements of the form \(a_{ii}\) are called the principal diagonal
Definition
A square matrix \(D\) is called diagonal if all entries off the principal diagonal are zero
Often written as
Diagonal matrixes are very nice to work with!
Example
Fact
If \(D = \mathrm{diag}(d_1, \ldots,d_n)\) then
\(D^k = \mathrm{diag}(d^k_1, \ldots, d^k_n)\) for any \(k \in \mathbb{N}\)
\(d_n \geq 0\) for all \(n\) \(\implies\) \(D^{1/2}\) exists and equals
\(d_n \ne 0\) for all \(n\) \(\implies\) \(D\) is nonsingular and
Fact
The eigenvalues of a diagonal matrix are the diagonal elements themselves.
Proof
The characteristic polynomial is given by
Therefore eigenvalues are \(d_1, \ldots, d_n\), that is diagonal elements of the matrix.
\(\blacksquare\)
Concept of diagonalization#
recall that two matrices are similar if there is a change of basis transformation \(P\) that connects the linear operators corresponding to these matrices such that \(A = P D P^{-1}\)
Definition
If \(A\) is similar to a diagonal matrix, then \(A\) is called diagonalizable
because diagonal matrices are easier to work with in many cases, diagonalization may be super useful in applications!
Example
Consider \(A\) that is similar to a diagonal matrix \(D = \mathrm{diag}(d_1,\dots,d_n)\).
To find the \(A^n\) we can use the fact that
and therefore it’s easy to show by mathematical induction that
Given the properties of the diagonal matrixes, we have an easily computed expression
Diagonalization using eigenpairs#
As you would anticipate, eigenvalues are most helpful in diagonalization
Fact (Diagonalizable \(\longrightarrow\) Eigenpairs)
Let \(n \times n\) matrix \(A\) be diagonalizable with \(A = P D P^{-1}\) and let
\(D = \mathrm{diag}(\lambda_1, \ldots, \lambda_n)\)
\(p_j\) for \(j=1,\dots,n\) be the columns of \(P\)
Then \((p_j, \lambda_j)\) is an eigenpair of \(A\) for each \(j \in \{1,\dots,n\}\)
Proof
From \(A = P D P^{-1}\) we get \(A P = P D\)
Equating \(n\)-th column on each side gives
Moreover \(p_n \ne {\bf 0}\) because \(P\) is invertible (otherwise determinant of \(P\) would be zero).
Fact (Distinct eigenvalues \(\longrightarrow\) diagonalizable)
If \(n \times n\) matrix \(A\) has \(n\) distinct eigenvalues \(\lambda_1, \ldots, \lambda_n\), then \(A\) is diagonalizable with \(A = P D P^{-1}\) where
\(D = \mathrm{diag}(\lambda_1, \ldots, \lambda_n)\)
each \(n\)-th column of \(P\) is equal to an normlized eigenvector for \(\lambda_n\)
Example
Let
The eigenvalues of \(A\) given by the equation
are \(\lambda_1=2\) and \(\lambda_2=4\), while the eigenvectors are given by the solutions
as \((p,-p)\) and \((q,-3q)\) where \(p\) and \(q\) are free parameters. Imposing that the norm of the eigenvectors should be 1, we find that the normalized eigenvectors are
Hence
import numpy as np
from numpy.linalg import inv
A = np.array([[1, -1],
[3, 5]])
eigvals, eigvecs = np.linalg.eig(A)
D = np.diag(eigvals)
P = eigvecs
print('A =',A,sep='\n')
print('D =',D,sep='\n')
print('P =',P,sep='\n')
print('P^-1 =',inv(P),sep='\n')
print('P*D*P^-1 =',P@D@inv(P),sep='\n')
A =
[[ 1 -1]
[ 3 5]]
D =
[[2. 0.]
[0. 4.]]
P =
[[-0.70710678 0.31622777]
[ 0.70710678 -0.9486833 ]]
P^-1 =
[[-2.12132034 -0.70710678]
[-1.58113883 -1.58113883]]
P*D*P^-1 =
[[ 1. -1.]
[ 3. 5.]]
Fact
Given \(n \times n\) matrix \(A\) with distinct eigenvalues \(\lambda_1, \ldots, \lambda_n\) we have
\(\det(A) = \prod_{j=1}^n \lambda_n\)
\(A\) is nonsingular \(\iff\) all eigenvalues are nonzero
Proof
The first statement follows from the properties of the determinant of a product:
For the second statement: \(A\) is nonsingular \(\iff\) \(\det(A) \ne 0\) \(\iff\) \(\prod_{j=1}^n \lambda_n \ne 0\) \(\iff\) all \(\lambda_n \ne 0\)
Diagonalization of symmetric matrices#
Recall that a matrix \(A\) is symmetric if \(A = A^T\)
Very special case when things work out much nicer!
Fact
Eigenvalues of a symmetric matrix are real numbers.
Proof
Complete proof requires complex analysis, but here is intuition for \(2 \times 2\) case.
The descriminant is nonnegative for any \(a,b,c\), and therefore the roots are real numbers.
Fact
Eigenvectors \(p_i\) of a symmetric matrix \(A\) corresponding to distinct eigenvalues \(\lambda_i\) are orthogonal.
Proof
Consider any \(i \ne j\) eigenvalues and eigenvectors
On the other hand, with transposition of \(1 \times 1\) “matrix” we have
Subtracting the two expressions gives
and since \(\lambda_i - \lambda_j \ne 0\), we have \(p_i \boldsymbol{\cdot} p_j = 0\)
\(\blacksquare\)
Example
The eigenvalues are \(\lambda_1 = -3\) and \(\lambda_2 = 5\).
The assiciated eigenvectors are of the form \((p,-p)\) and \((q,q)\) where \(p\) and \(q\) are free parameters. We have
that is (all possible) eigenvectors are orthogonal.
This is now sufficient to conclude that when all eigenvalues of a symmetric matrix are distinct, it is possible to diagonalize the matrix using the eigenvectors in the transfomation matrix, and because they form an orthogonal set, it is possible to ensure that the transformation matrix is orthogonal \(\to\) easier to work with
Algorithm:
Find eigenvalues \(\lambda_1, \ldots, \lambda_n\) of \(A\), assume they are all different (distinct)
For each \(\lambda_i\) find the corresponding eigenvector \(p_i\)
Form the othonormal set of eigenvectors \(p_1, \ldots, p_n\)
Form the transformation matrix \(P\) from these eigenvectors, it is orthogonal
Form the diagonal matrix \(D\) with the eigenvalues on the diagonal
The matrix \(A\) can be diagonalized as \(A = P D P^T\)
However, even though the case of repeated eigenvalues is more involved and requires more advanced techniques, the following fact still holds
Fact
For any symmetric matrix \(A\), it is possible to form an orthonormal basis from its eigenvectors.
The symmetric matrix \(A\) can be diagonalized by an orthogonal transformation matrix formed from these eigenvectors.
Proof
Intuition:
Distinct eigenvalues \(\to\) complete set of eigenvalues to form the bases.
Even when eigenvalues are not distinct, each repeated eigenvalue corresponds to the subspace with dimension equal to the multiplicity of the eigenvalue \(\to\) still possible to form a basis.
Orthogonality of eigenvectors \(\to\) orthonormality of the basis.
It is always possible to normalize the basis vectors \(\to\) transformation matrix is orthogonal.
The only practical issue is multiplicity of eigenvalues, in which case finding the required eigenvectors to form the orthonormal basis requires more careful work.