📖 Determinants, eigenpairs and diagonalization#
⏱ | words
WARNING
This section of the lecture notes is still under construction. It will be ready before the lecture.
Eigenvalues and Eigenvectors#
Let \(A\) be a square matrix
Think of \(A\) as representing a mapping \(x \mapsto A x\), this is a linear function (see prev lecture)
But sometimes \(x\) will only be scaled:
Definition
If \(A x = \lambda x\) holds and \(x\) is nonzero, then
\(x\) is called an eigenvector of \(A\) and \(\lambda\) is called an eigenvalue
\((x, \lambda)\) is called an eigenpair
Clearly \((x, \lambda)\) is an eigenpair of \(A\) \(\implies\) \((\alpha x, \lambda)\) is an eigenpair of \(A\) for any nonzero \(\alpha\)
Example
Let
Then
form an eigenpair because \(x \ne 0\) and
import numpy as np
A = [[1, 2],
[2, 1]]
eigvals, eigvecs = np.linalg.eig(A)
for i in range(eigvals.size):
x = eigvecs[:,i]
lm = eigvals[i]
print(f'Eigenpair {i}:\n{lm:.5f} --> {x}')
print(f'Check Ax=lm*x: {np.dot(A, x)} = {lm * x}')
Eigenpair 0:
3.00000 --> [0.70710678 0.70710678]
Check Ax=lm*x: [2.12132034 2.12132034] = [2.12132034 2.12132034]
Eigenpair 1:
-1.00000 --> [-0.70710678 0.70710678]
Check Ax=lm*x: [ 0.70710678 -0.70710678] = [ 0.70710678 -0.70710678]
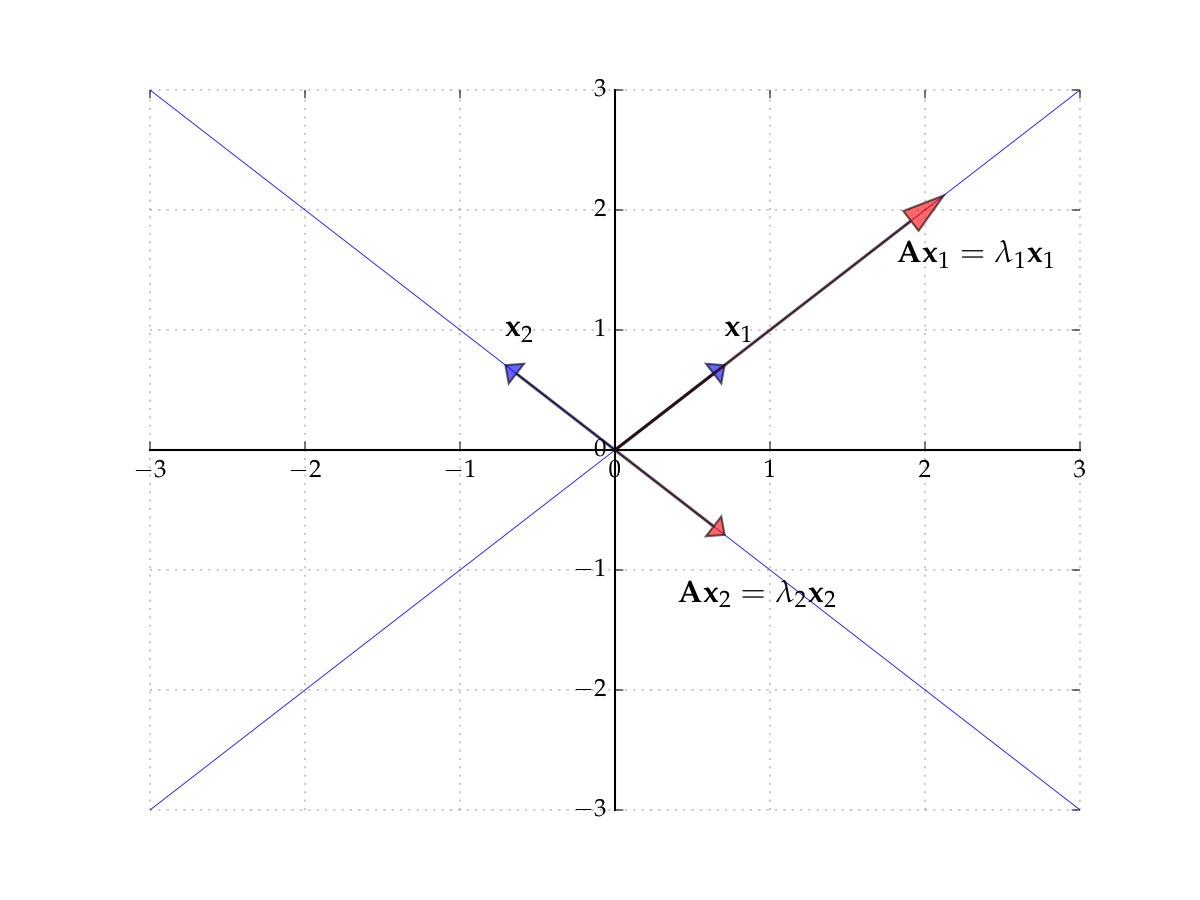
Fig. 42 The eigenvectors of \(A\)#
Consider the matrix
Induces counter-clockwise rotation on any point by \(90^{\circ}\)
Hint
The rows of the matrix show where the classic basis vectors are translated to.
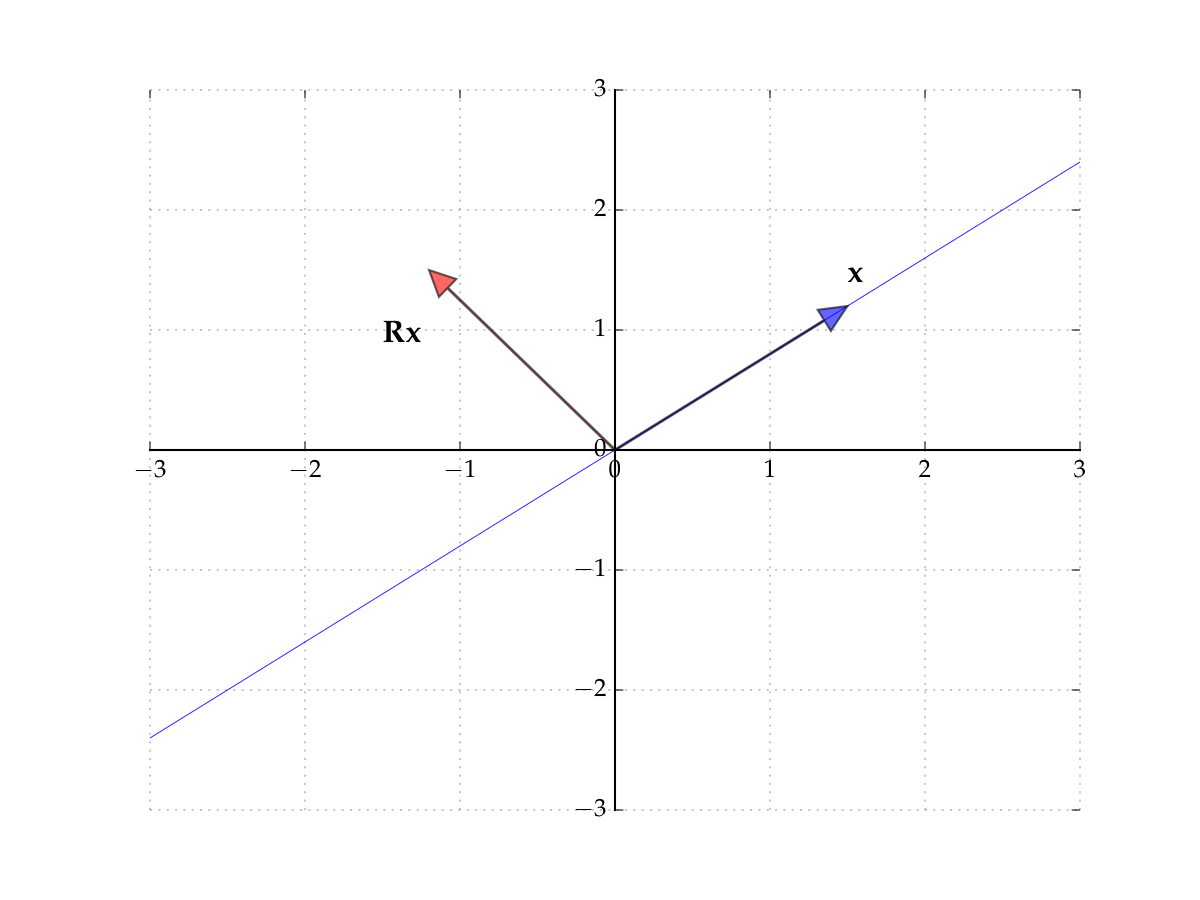
Fig. 43 The matrix \(R\) rotates points by \(90^{\circ}\)#
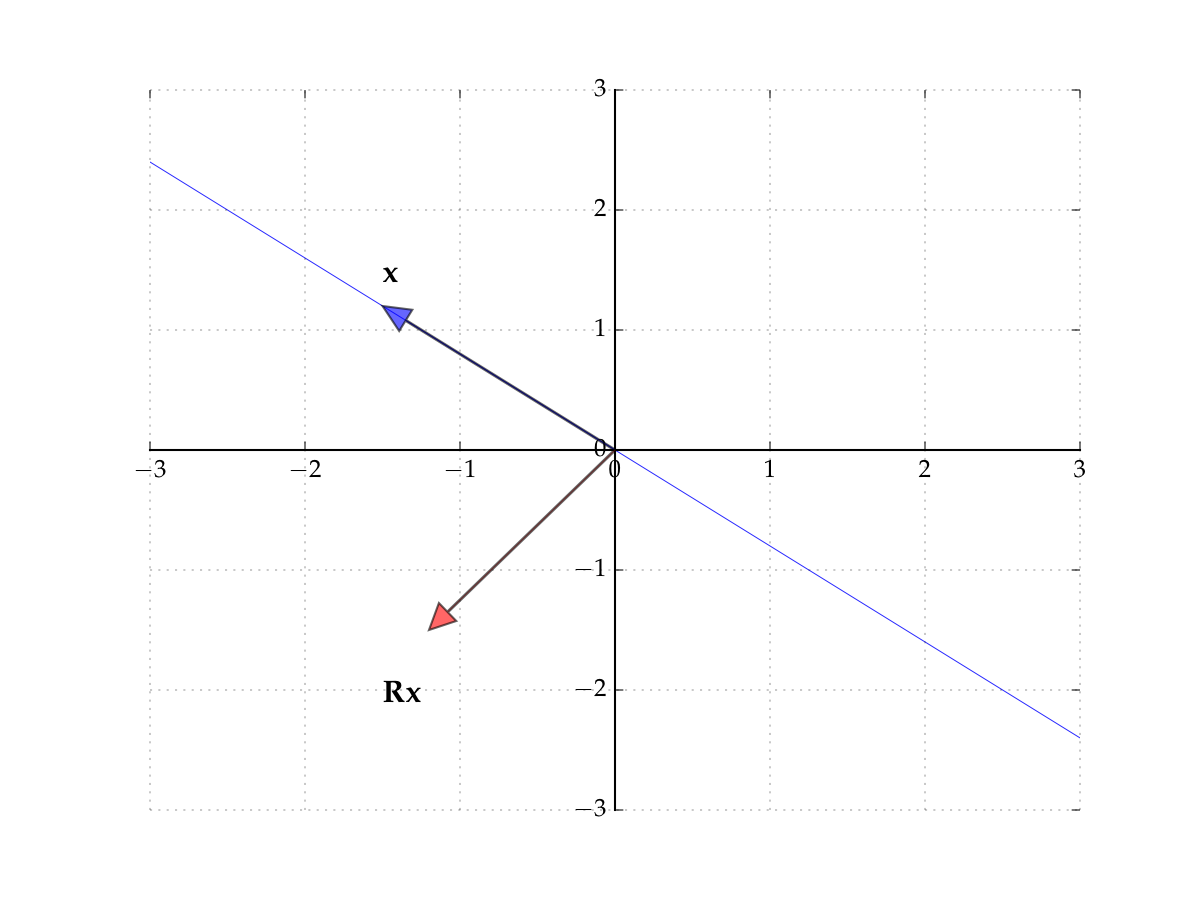
Fig. 44 The matrix \(R\) rotates points by \(90^{\circ}\)#
Hence no point \(x\) is scaled
Hence there exists no pair \(\lambda \in \mathbb{R}\) and \(x \ne 0\) such that
In other words, no real-valued eigenpairs exist. However, if we allow for complex values, then we can find eigenpairs even for this case
Eigenvalues and determinants#
Fact
For any square matrix \(A\)
Proof
Let \(A\) by \(N \times N\) and let \(I\) be the \(N \times N\) identity
We have
Example
In the \(2 \times 2\) case,
Hence the eigenvalues of \(A\) are given by the two roots of
Equivalently,
Existence of Eigenvalues#
For an \((N \times N)\) matrix \(A\) expression \(\det(A - \lambda I) = 0\) is a polynomial equation of degree \(N\) in \(\lambda\)
to see this, imagine how \(\lambda\) enters into the computation of the determinant using the definition along the first row, then first row of the first minor submatrix, and so on
the highest degree of \(\lambda\) is then the same as the dimension of \(A\)
Definition
The polynomial \(\det(A - \lambda I)\) is called a characteristic polynomial of \(A\).
The roots of the characteristic equation \(\det(A - \lambda I) = 0\) determine all eigenvalues of \(A\).
By the Fundamental theorem of algebra there are \(N\) of such (complex) roots \(\lambda_1, \ldots, \lambda_N\), and we can write
Each such \(\lambda_i\) is an eigenvalue of \(A\) because
Note: not all roots are necessarily distinct — there can be repeats
Diagonalization#
Consider a square \(N \times N\) matrix \(A\)
Definition
The \(N\) elements of the form \(a_{nn}\) are called the principal diagonal
Definition
A square matrix \(D\) is called diagonal if all entries off the principal diagonal are zero
Often written as
Diagonal matrixes are very nice to work with!
Example
Fact
If \(D = \mathrm{diag}(d_1, \ldots,d_N)\) then
\(D^k = \mathrm{diag}(d^k_1, \ldots, d^k_N)\) for any \(k \in \mathbb{N}\)
\(d_n \geq 0\) for all \(n\) \(\implies\) \(D^{1/2}\) exists and equals
\(d_n \ne 0\) for all \(n\) \(\implies\) \(D\) is nonsingular and
Example
Let’s find eigenvalues and eigenvectors of \(D = \mathrm{diag}(d_1, \ldots,d_N)\).
The characteristic polynomial is given by
Therefore the diagonal elements are the eigenvalues of \(D\)!
Change of basis#
Consider a vector \(x\in \mathbb{R}^N\) which has coordinates \((x_1,x_2,\dots,x_N)\) in classis basis \((e_1,e_2,\dots,e_N)\), where \(e_i = (0,\dots,0,1,0\dots,0)^T\)
Coordinates of a vector is what we call the coefficients of the linear combination of the basis vectors that gives the vector
We have
Consider a different basis in \(\mathbb{R}^N\) (recall the definition) denoted \((e'_1,e'_2,\dots,e'_N)\) Here we assume that each \(e'_i\) is written in the coordinates corresponding to the original basis \((e_1,e_2,\dots,e_N)\).
The coordinates of vector \(x\) in basis \((e'_1,e'_2,\dots,e'_N)\) denoted \(x' = (x'_1,x'_2,\dots,x'_N)\) are by definition
Definition
The transformation matrix from the basis \((e_1,e_2,\dots,e_N)\) to \((e'_1,e'_2,\dots,e'_N)\) is given by
In other words, the same vector has coordinates \(x = (x_1,x_2,\dots, x_N)\) in the original basis \((e_1,e_2,\dots,e_N)\) and \(x' = (x'_1,x'_2,\dots, x'_N)\) in the new basis \((e'_1,e'_2,\dots,e'_N)\), and it holds
We now have a way to represent the same vector in different bases, i.e. change basis!
Example
Fact
The transformation matrix \(P\) is nonsingular (invertible).
Proof
Because the transformation matrix maps a set of basis vectors to another set of basis vectors, they are linearly independent. By the properties of linear functions, \(P\) is then non-singular, and \(P^{-1}\) exists. \(\blacksquare\)
Linear functions in different bases#
Consider a linear map \(A: x \mapsto Ax\) where \(x \in \mathbb{R}^N\)
Can we express the same linear map in a different basis?
Let \(B\) be the matrix representing the same linear map in a new basis, where the transformation matrix is given by \(P\).
If the linear map is the same, we must have
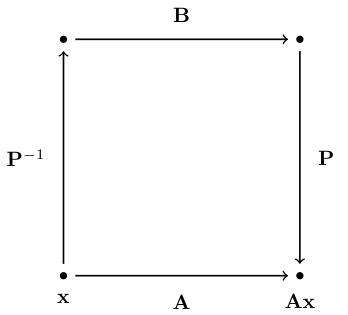
Definition
Square matrix \(A\) is said to be similar to square matrix \(B\) if there exist an invertible matrix \(P\) such that \(A = P B P^{-1}\).
Similar matrixes also happen to be very useful!
Example
Consider \(A\) that is similar to a diagonal matrix \(D = \mathrm{diag}(d_1,\dots,d_N)\).
To find the \(A^n\) we can use the fact that
and therefore it’s easy to show by mathematical induction that
Given the properties of the diagonal matrixes, we have an easily computed expression
Diagonalization using eigenvectors#
Definition
If \(A\) is similar to a diagonal matrix, then \(A\) is called diagonalizable
Fact (Diagonalizable \(\longrightarrow\) Eigenpairs)
Let \(A\) be diagonalizable with \(A = P D P^{-1}\) and let
\(D = \mathrm{diag}(\lambda_1, \ldots, \lambda_N)\)
\(p_n\) for \(n=1,\dots,N\) be the columns of \(P\)
Then \((p_n, \lambda_n)\) is an eigenpair of \(A\) for each \(n\)
Proof
From \(A = P D P^{-1}\) we get \(A P = P D\)
Equating \(n\)-th column on each side gives
Moreover \(p_n \ne 0\) because \(P\) is invertible (which facts?)
Fact (Distinct eigenvalues \(\longrightarrow\) diagonalizable)
If \(N \times N\) matrix \(A\) has \(N\) distinct eigenvalues \(\lambda_1, \ldots, \lambda_N\), then \(A\) is diagonalizable as \(A = P D P^{-1}\) where
\(D = \mathrm{diag}(\lambda_1, \ldots, \lambda_N)\)
each \(n\)-th column of \(P\) is equal to the eigenvector for \(\lambda_n\)
Example
Let
The eigenvalues of \(A\) are 2 and 4, while the eigenvectors are
Hence
import numpy as np
from numpy.linalg import inv
A = np.array([[1, -1],
[3, 5]])
eigvals, eigvecs = np.linalg.eig(A)
D = np.diag(eigvals)
P = eigvecs
print('A =',A,sep='\n')
print('D =',D,sep='\n')
print('P =',P,sep='\n')
print('P^-1 =',inv(P),sep='\n')
print('P*D*P^-1 =',P@D@inv(P),sep='\n')
A =
[[ 1 -1]
[ 3 5]]
D =
[[2. 0.]
[0. 4.]]
P =
[[-0.70710678 0.31622777]
[ 0.70710678 -0.9486833 ]]
P^-1 =
[[-2.12132034 -0.70710678]
[-1.58113883 -1.58113883]]
P*D*P^-1 =
[[ 1. -1.]
[ 3. 5.]]
Profit!#
Fact
Given \(N \times N\) matrix \(A\) with distinct eigenvalues \(\lambda_1, \ldots, \lambda_N\) we have
If \(A = \mathrm{diag}(d_1, \ldots, d_N)\), then \(\lambda_n = d_n\) for all \(n\)
\(\det(A) = \prod_{n=1}^N \lambda_n\)
If \(A\) is symmetric, then \(\lambda_n \in \mathbb{R}\) for all \(n\) (not complex!)
Proof
The first statement can be checked directly by verifying that the classic basis vectors are eigenvectors of \(A\).
The second statement follows from the properties of the determinant of a product:
The third statement requires complex analysis, we take for granted.
Fact
\(A\) is nonsingular \(\iff\) all eigenvalues are nonzero
Proof
\(A\) is nonsingular \(\iff\) \(\det(A) \ne 0\) \(\iff\) \(\prod_{n=1}^N \lambda_n \ne 0\) \(\iff\) all \(\lambda_n \ne 0\)
Fact
If \(A\) is nonsingular, then eigenvalues of \(A^{-1}\) are \(1/\lambda_1, \ldots, 1/\lambda_N\)
Proof
Diagonalization of symmetric matrices#

References and reading#
References
[Simon and Blume, 1994]: chapters~9, 23 (excluding complex number)
[Sundaram, 1996]: 1.3.4-1.3.6
Further reading and self-learning
Excellent visualizations of concepts covered in this lecture, strongly recommended for further study 3Blue1Brown: Essence of linear algebra